Serving ML Models in Production with FastAPI and Celery
Overview
This article talks about how to implement Machine Learning in a real project. An example to implement a Machine Learning model using Celery and FastAPI. All the code can be found in the archive here. Github. Vietnamese version can be read at Vie.
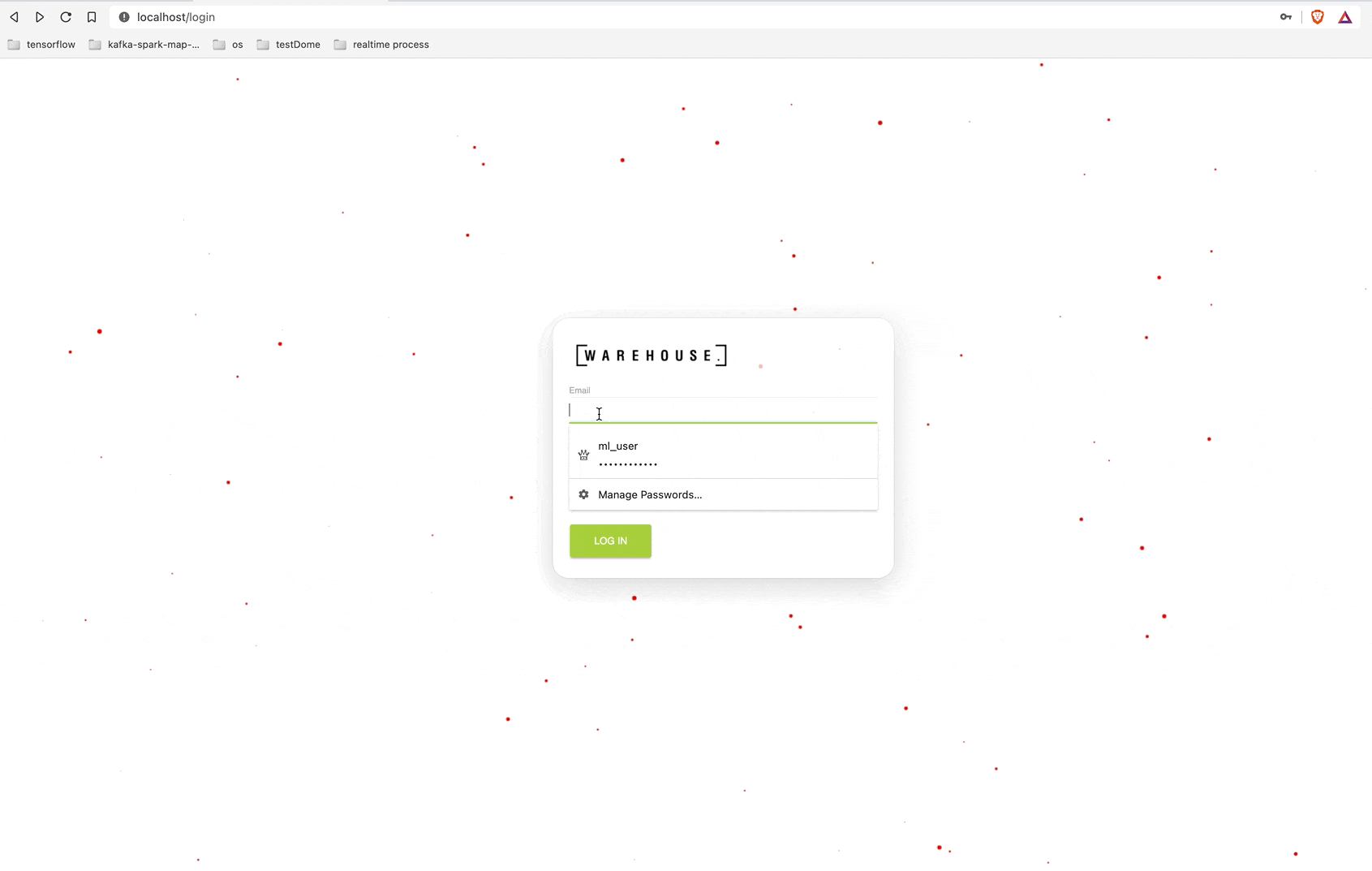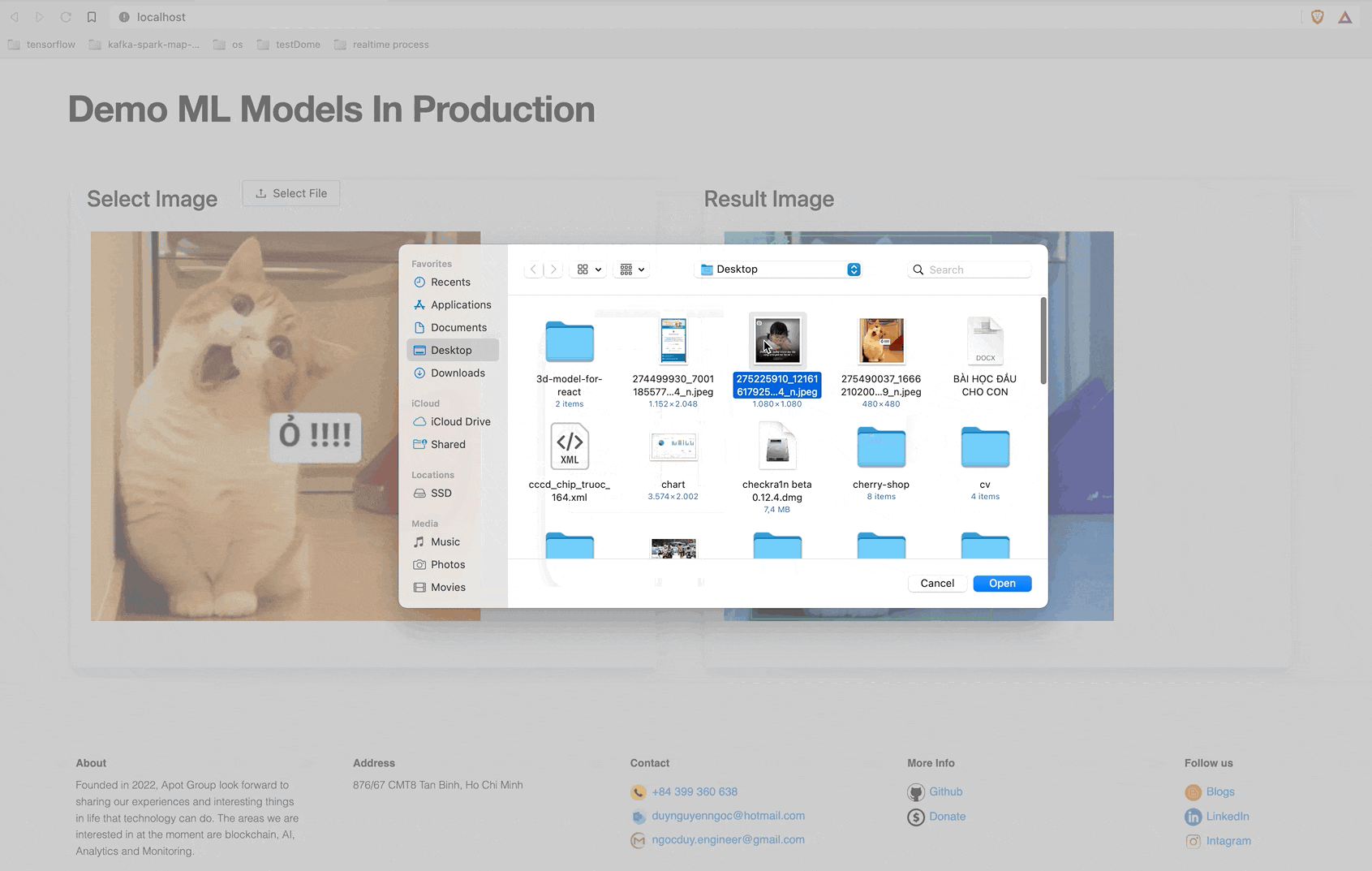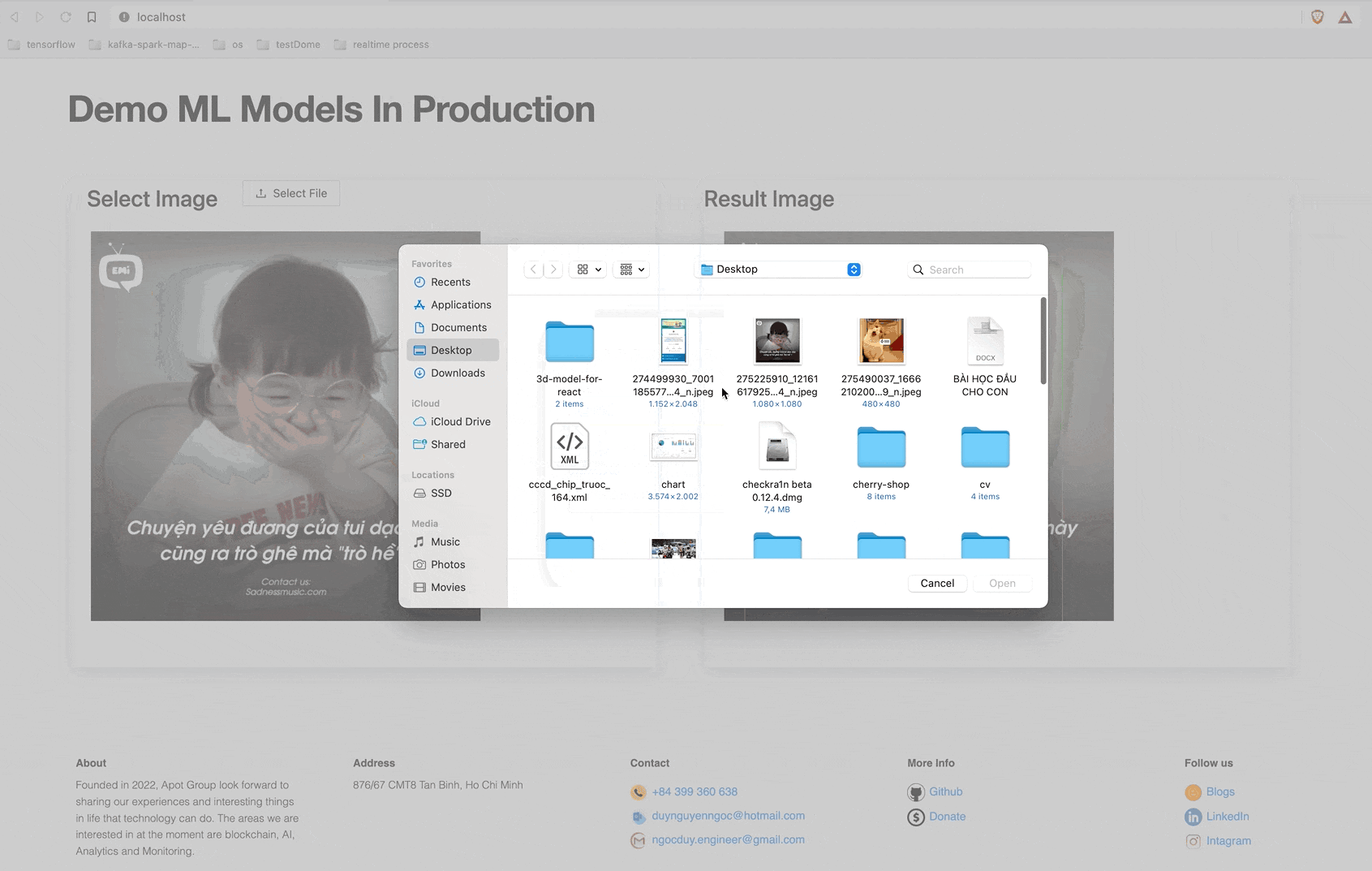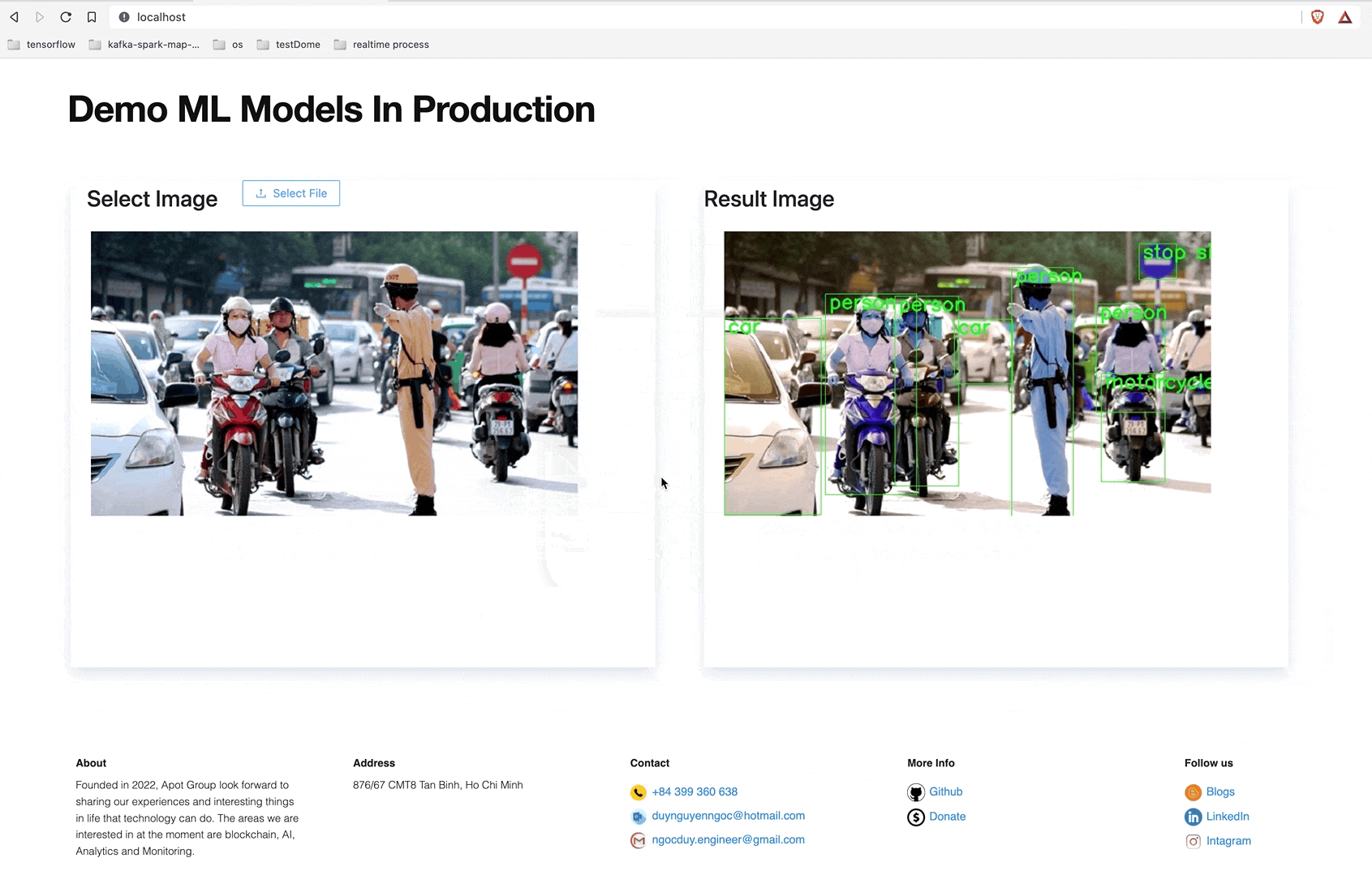
In this tutorial we use the object-detection model trained with Tensorflow base on Coco Dataset. In general, it is an object recognition model with about 80 classes such as dogs, cats, birds (birds), chickens, ducks … Instructions to train the model are not mentioned in this article.
Asynchronous
The goal is to build the service asynchronously: instead of directly returning a prediction (the client calls the ML Service and waits for the service to return the result), the ML Service returns a unique identifier (task_id) for the a mission. While the prediction task is being completed by the ML Service (Worker Node), the Client is free to continue processing other tasks for example sending another prediction request. The steps below describe the actions taken to process a prediction (internet source image):
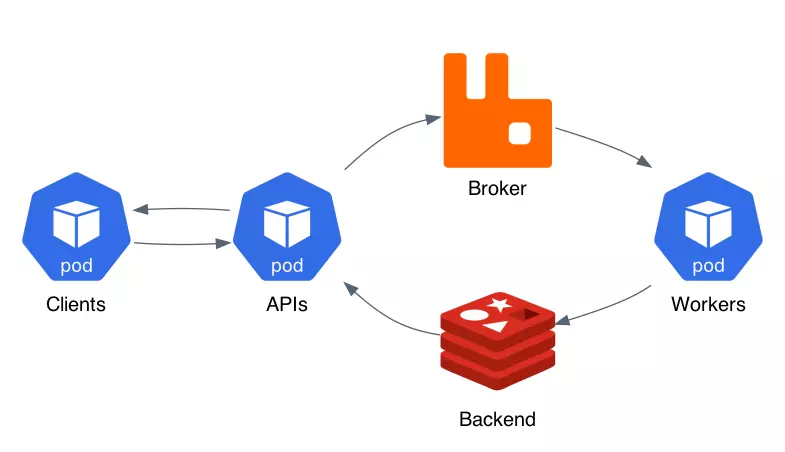
- The client application sends a POST request to the FastAPI endpoint, depending on the request sends to the API service different content in this case uploading an image to be predicted.
- FastAPI validates the information and saves the image to the archive (eg: Nas, HDFS…). If the validation is successful then a prediction task will be created and moved to the Broker - Message queue (e.g. RabbitMQ).
- At the same time, the API service also creates a unique task_id and returns the client if the Celery task creation is successful.
- The prediction task is assigned by the Broker to one of the Worker Nodes (here you can have multiple worker nodes). Once the task is distributed, the worker generates a prediction using the previously trained ML model.
- Once a prediction has been generated, the results are stored in the Celery backend (eg Redis).
- At any point after step 3, the Client can start examining the results from another FastAPI endpoint using the unique task_id received from the previous API service. Once the prediction is ready, it will be returned to the Client.
Let’s start
I continue to use Docker to develop this application.
- First proceed to clone the repo to:
# clone git repo and goto root path
git clone https://github.com/apot-group/ml-models-in-production.git
cd ml-models-in-production
- The project structure includes:
├── ml-api -> Contains code of FastAPI service config at ml-api/app/environment.env
├── ml-celery -> Contains code of Celery Worker config at ml-celery/app/environment.env
├── ml-client -> Contains Client's code
├── ml-storages -> Create a shared storage like file system service
├── upload
├── object-detection
├── docker-compose.yaml -> run service with this!
...
- Next, we need to build the entire service with docker-compose:
docker-compose build && docker-compose up
Since building the image from scratch, this can take a while. After executing the docker-compose up command, the services will start. It can take a while before everything is up and running.
| Service | URL | User/Password |
| -------------| ----------------------------|---------------------------------|
| Client | http://localhost | ml_user/CBSy3NaBMxLF |
| API | http://localhost/api/docs | None |
- Finally, login to http://localhost with user “ml_user” and pass
CBSy3NaBMxLFselect the file you need to predict and see the results.
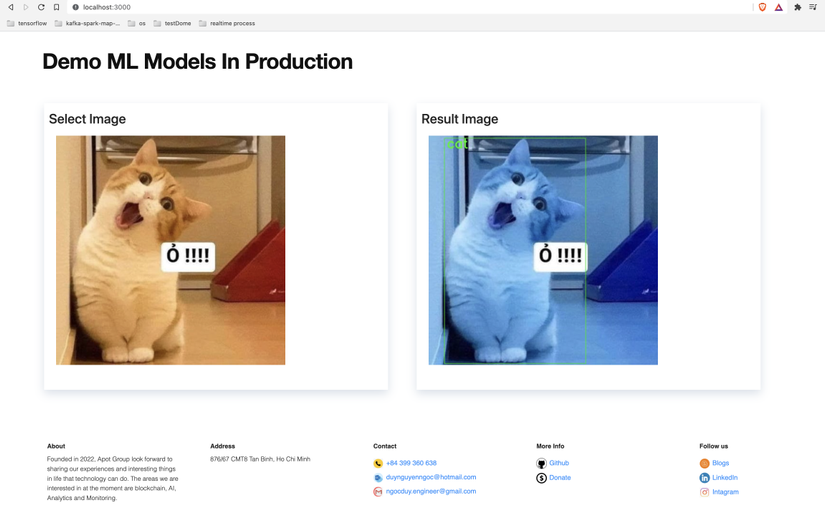
Note that the first image predicted will take some time because Celery needs time to load the ML model into memory. From the 2nd image onwards the service runs pretty fast.
This is just a reference example of the approach to implementing an ML model. In fact requires more things. Hope this article can help you something. Cordially greet and to win!